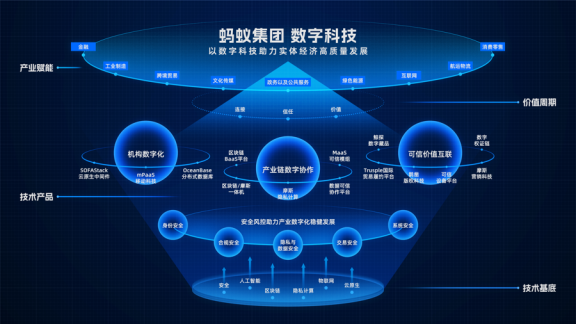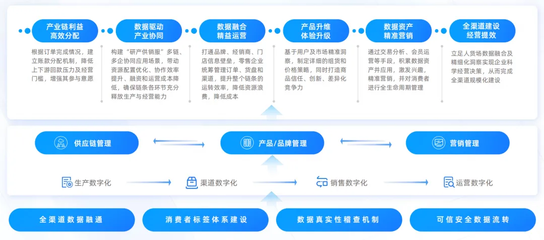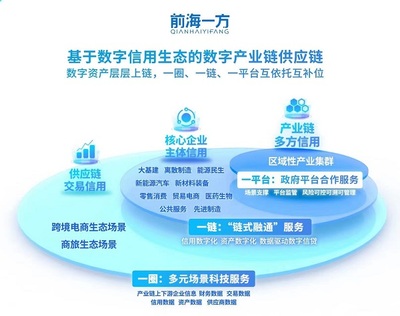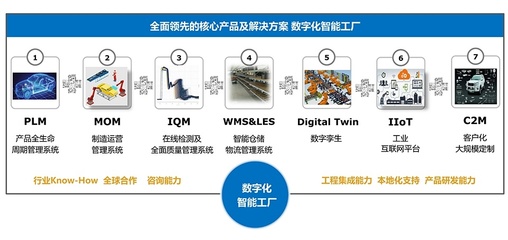
在數字經濟浪潮席卷全球的今天,企業面臨著前所未有的挑戰與機遇。傳統增長模式遭遇瓶頸,同質化競爭日趨激烈,而消費者需求日益個性化、即時化。在此背景下,一場深刻的“轉型”迫在眉睫,“破局”之道成為企業生存與發展的關鍵命題。單純的技術引入已不足以構建護城河,如何將數字技術,特別是聚焦于“人”的數字化會員服務,轉化為可持續的競爭優勢,正成為重塑企業競爭力的核心引擎。
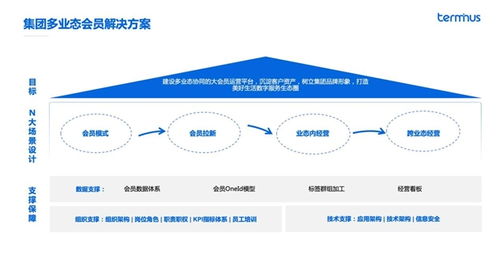
數字化會員體系,遠非傳統積分卡的電子化。它是企業利用大數據、云計算、人工智能等數字技術,與用戶建立深度、持續且個性化連接的戰略性基礎設施。其核心在于,將一次性的交易關系,升級為全生命周期的價值共生關系。通過無縫的線上線下體驗、精準的用戶畫像分析、個性化的產品與服務推薦,以及階梯式的權益與激勵,企業能夠牢牢鎖定用戶注意力,提升忠誠度,并從海量交互數據中洞察未來趨勢。
數字技術是這一體系高效運轉的“技術服務”基石。云平臺提供了彈性可擴展的數據存儲與處理能力,確保千萬級乃至億級會員數據的穩定運營。大數據分析技術能夠對會員行為進行多維度拆解,形成360度視圖,為精準營銷和產品迭代提供決策依據。人工智能與機器學習算法,使得實時個性化推薦、智能客服、動態定價成為可能,極大提升了服務效率和用戶體驗。物聯網、移動支付等技術則保障了會員權益在多元場景下的順暢核銷與貫通,打破渠道壁壘。
這種由數字化會員驅動的新型競爭力,主要體現在三大維度:
- 深化客戶洞察,驅動精準創新:企業通過會員的消費軌跡、互動偏好、反饋數據,能夠以前所未有的顆粒度理解市場需求。這不僅能用于優化現有營銷策略,更能反哺產品研發與供應鏈管理,實現從“生產什么賣什么”到“用戶需要什么就提供什么”的C2B轉變,從而在源頭構建差異化優勢。
- 提升生命周期價值,優化營收結構:忠誠的會員復購率更高,對價格敏感度更低,且更愿意嘗試品牌的新產品與新服務。通過精細化運營,企業可以有效提升會員的活躍度、消費頻次與客單價,將單次交易價值擴展為終身價值。會員費、增值服務等模式還能為企業帶來更穩定、高質量的經常性收入。
- 構建品牌生態,加固競爭壁壘:一個活躍的數字化會員社群本身就是強大的品牌資產。企業可以以此為基礎,延伸服務邊界,跨界聯合合作伙伴,打造以自身為核心的生態系統。會員數據與關系的沉淀,形成了難以被競爭對手快速復制的軟性壁壘,使企業的競爭力從單一的產品或價格層面,上升到生態系統協同的層面。
成功之路并非坦途。企業需警惕將數字化會員簡單視為促銷工具,而應將其納入整體戰略;必須高度重視數據安全與隱私保護,以誠信換取用戶長久信賴;需要打破內部數據孤島,構建跨部門協同的運營組織,確保技術能力與業務目標深度融合。
總而言之,在數字化轉型的深水區,以“數字化會員”為核心抓手,深度融合前沿“數字技術服務”,是企業實現轉型破局、重塑競爭力的關鍵路徑。它標志著競爭焦點從“流量”爭奪轉向“留量”運營,從“產品為中心”轉向“用戶為中心”。能夠真正以數據驅動、深度連接并賦能每一位會員的企業,必將在激烈的市場格局中贏得主動,建立持久而強大的新競爭力。